
A database must reflect the business processes of an organization. This fundamental principle underpins efficient data management and successful business operations. Ignoring this leads to data inconsistencies, operational bottlenecks, and ultimately, business failure. This exploration delves into the crucial relationship between database design and business processes, examining how accurate data modeling, robust data integrity, and scalable database architectures are essential for aligning technology with organizational goals. We’ll uncover how effective database strategies can drive business growth and enhance operational efficiency.
From designing relational database schemas that mirror real-world processes to implementing data validation rules that prevent fraud, we will explore practical examples and best practices across various industries. We’ll also address the challenges of migrating legacy systems, ensuring data security, and adapting databases to evolving business needs. The goal is to provide a comprehensive understanding of how a well-designed database can be a powerful tool for achieving business objectives.
Data Modeling and Business Processes
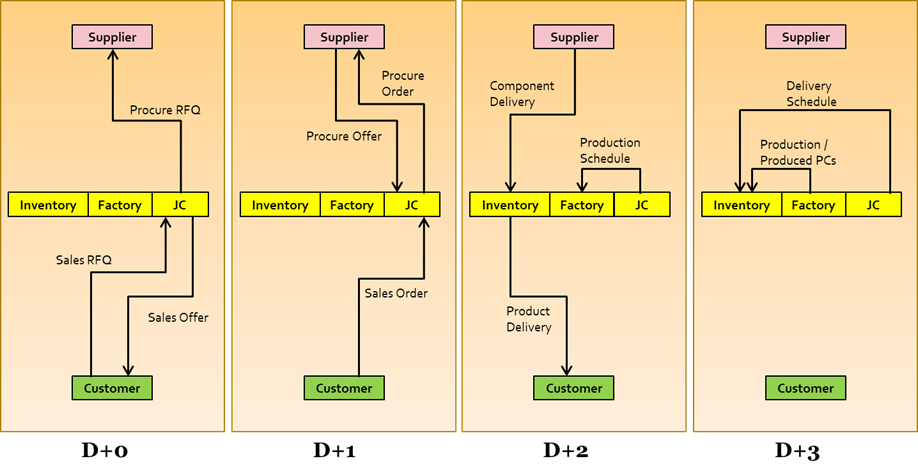
Effective data modeling is crucial for aligning a database with an organization’s business processes. A well-designed database schema accurately reflects the flow of information, enabling efficient data retrieval and analysis. Conversely, a poorly designed schema can lead to data inconsistencies, inefficiencies, and ultimately, hinder the organization’s ability to achieve its objectives. This section explores the relationship between data modeling and business processes within the context of an e-commerce order fulfillment system and broader supply chain management.
Relational Database Schema for E-commerce Order Fulfillment
A relational database for an e-commerce business can be structured around several key tables. These tables represent core entities and their relationships, allowing for efficient tracking of orders from initiation to completion. The following schema illustrates a simplified model:
| Table Name | Columns | Data Type | Constraints |
|---|---|---|---|
| Customers | CustomerID (PK), FirstName, LastName, Email, Address | INT, VARCHAR, VARCHAR, VARCHAR, VARCHAR | CustomerID is unique |
| Products | ProductID (PK), ProductName, Description, Price, StockQuantity | INT, VARCHAR, VARCHAR, DECIMAL, INT | ProductID is unique |
| Orders | OrderID (PK), CustomerID (FK), OrderDate, TotalAmount | INT, INT, DATE, DECIMAL | OrderID is unique, CustomerID references Customers |
| OrderItems | OrderItemID (PK), OrderID (FK), ProductID (FK), Quantity, Price | INT, INT, INT, INT, DECIMAL | OrderItemID is unique, OrderID references Orders, ProductID references Products |
| Payments | PaymentID (PK), OrderID (FK), PaymentMethod, PaymentDate, Amount | INT, INT, VARCHAR, DATE, DECIMAL | PaymentID is unique, OrderID references Orders |
This schema utilizes primary keys (PK) and foreign keys (FK) to establish relationships between tables, ensuring data integrity and enabling efficient querying. For instance, the `OrderItems` table links `Orders` and `Products`, detailing the items included in each order.
Challenges of Mapping Informal Business Processes to Formal Database Structures
Translating informal, often undocumented, business processes into a formal database structure presents significant challenges. One major hurdle is the ambiguity inherent in informal processes. For example, an unwritten rule about order prioritization based on customer loyalty might be difficult to represent in a database without a dedicated field for loyalty status. Another challenge lies in handling exceptions and variations. Informal processes often accommodate exceptions not explicitly defined in written procedures. Capturing these exceptions requires careful analysis and potentially more complex database design, possibly involving additional tables or flags. Finally, the evolving nature of business processes adds complexity. As processes change, the database schema must adapt, potentially requiring significant modifications and testing.
Data Modeling Techniques for Cyclical and Linear Processes
Linear business processes, such as order fulfillment (from order placement to delivery), are well-suited to relational databases using techniques like Entity-Relationship Diagrams (ERD). The sequential nature of the process maps easily to tables with clear relationships. Cyclical processes, like customer relationship management (CRM), involving repeated interactions, are more challenging. Techniques like state machines or process modeling languages (BPMN) can complement ERD to capture the iterative nature of the process. For example, a CRM system might track customer interactions through different stages (e.g., prospect, lead, customer, advocate) which could be represented using additional tables or attributes indicating the current stage. The choice of modeling technique depends heavily on the complexity and nature of the business process.
Supply Chain Management Entity-Table Relationships
The following table illustrates the relationship between business entities and database tables in a supply chain management system.
| Business Entity | Database Table | Key Attributes | Relationships |
|---|---|---|---|
| Supplier | Suppliers | SupplierID, Name, ContactInfo | One-to-many with Products |
| Product | Products | ProductID, Name, Description, SupplierID (FK) | Many-to-one with Suppliers, One-to-many with Inventory, One-to-many with Orders |
| Inventory | Inventory | InventoryID, ProductID (FK), Quantity, WarehouseLocation | Many-to-one with Products |
| Warehouse | Warehouses | WarehouseID, Location | One-to-many with Inventory |
This table demonstrates how various entities within the supply chain are represented as tables, with relationships defined through foreign keys. For example, a product is linked to its supplier and the inventory it holds in various warehouses. The relationships ensure data integrity and allow for efficient tracking of products throughout the supply chain.
Data Integrity and Business Rules
Data integrity and the enforcement of business rules are paramount in ensuring the accuracy, reliability, and trustworthiness of any database system. A well-designed database, particularly in critical sectors like healthcare and finance, leverages constraints and automated processes to maintain data consistency and prevent errors that could have significant consequences. This section details how these mechanisms work within different application contexts.
Database Constraints in a Hospital’s Patient Management System
Database constraints are crucial for enforcing business rules within a hospital’s patient management system. Primary keys uniquely identify each patient record, preventing duplicate entries. Foreign keys establish relationships between tables, ensuring referential integrity. For example, a foreign key linking the `Patients` table (with a primary key `PatientID`) to the `Appointments` table (with a foreign key `PatientID`) guarantees that every appointment record refers to an existing patient. Check constraints limit the acceptable values for specific fields; for instance, a check constraint could ensure that `Age` is always a non-negative integer. These constraints, enforced at the database level, prevent data entry errors and maintain data consistency, directly supporting the hospital’s operational efficiency and patient safety. Violation of these constraints would result in the database rejecting the invalid data entry, preventing corrupted data from entering the system.
Implications of Data Inconsistency in a Database
Inconsistencies between a database’s data and the actual business processes it represents lead to a range of problems. For example, if a patient’s allergy information in the database is outdated or incorrect, it could lead to adverse reactions during treatment. In a retail setting, inaccurate inventory data could result in stockouts or overstocking, leading to lost sales or increased storage costs. In financial institutions, inconsistent transaction data could lead to incorrect account balances, fraudulent activities, and regulatory non-compliance. These inconsistencies erode trust in the system and can have serious financial and operational implications. A discrepancy between the database record of a patient’s blood type and the actual blood type could have life-threatening consequences.
Automating Business Rules: Triggers and Stored Procedures for Inventory Management
Database triggers and stored procedures automate the enforcement of business rules in a retail setting’s inventory management system. A trigger could automatically update inventory levels upon a sale, ensuring that the database reflects real-time stock quantities. A stored procedure could calculate reorder points based on sales history and lead times, automatically generating purchase orders when stock levels fall below a predefined threshold. This automation improves accuracy, reduces manual intervention, and enhances operational efficiency. For example, a trigger could be designed to automatically decrement the quantity of an item in stock when a sale is processed, and a stored procedure could be used to automatically generate a purchase order when the stock level of a specific item falls below a predefined minimum threshold.
Data Validation Rules and Fraud Prevention in Financial Transactions
Data validation rules are essential in preventing fraudulent activities within a financial institution’s transaction processing system. These rules can check for unusual transaction patterns, such as unusually large transactions or transactions originating from unusual locations. They can also verify the authenticity of transaction data, ensuring that it conforms to expected formats and ranges. For instance, a validation rule might check if the transaction amount exceeds a predefined threshold and require additional authorization. Another rule could verify the validity of a credit card number using a checksum algorithm. These checks, performed at the database level, provide a critical layer of security and help detect and prevent fraudulent transactions before they are processed. A system might flag a transaction as suspicious if it involves a large sum of money transferred to an account in a high-risk jurisdiction.
Database Design and Business Scalability

Database design significantly impacts a business’s ability to scale and adapt to growth. A well-structured database, employing appropriate techniques and technologies, ensures efficient data management even as data volumes and user traffic increase dramatically. Conversely, a poorly designed database can become a significant bottleneck, hindering performance and ultimately impacting the bottom line. This section explores how various design choices affect scalability, focusing on normalization, database system selection, partitioning, and replication strategies.
Database Normalization and Social Media Platform Efficiency
Normalization, the process of organizing data to reduce redundancy and improve data integrity, is crucial for the scalability of a rapidly growing social media platform. Consider a platform with millions of users, each posting frequently. Without normalization, storing user data, posts, comments, and likes might lead to massive data duplication. For instance, each post might redundantly store the user’s name and profile picture. Normalizing the database into multiple related tables (e.g., users, posts, comments, likes) eliminates this redundancy. This reduction in data size improves query performance, as the database needs to access less data to answer a request. Further, normalized databases are easier to update and maintain, as changes to user information only need to be made in one location, avoiding inconsistencies across multiple tables. The improved efficiency and reduced storage requirements directly translate to cost savings and enhanced scalability as the platform’s user base expands.
Comparison of Relational and NoSQL Databases for Business Processes
Relational Database Management Systems (RDBMS) like MySQL, PostgreSQL, and Oracle excel in structured data management, offering ACID properties (Atomicity, Consistency, Isolation, Durability) ensuring data integrity. They are ideal for applications requiring strict data consistency and transactional integrity, such as financial systems or inventory management. However, RDBMS can struggle with massive volumes of unstructured or semi-structured data and high-velocity data ingestion common in applications like social media or IoT platforms.
NoSQL databases, in contrast, offer greater flexibility and scalability, handling large volumes of diverse data types. Different NoSQL types—document databases (MongoDB), key-value stores (Redis), graph databases (Neo4j), and column-family stores (Cassandra)—cater to various needs. A social media platform might leverage a NoSQL database for storing user posts and interactions, while an e-commerce platform could use a relational database for managing product inventory and customer orders. The choice depends on the specific business process requirements and the nature of the data being managed. For instance, a real-time analytics dashboard might benefit from the speed of a key-value store, while a complex social graph analysis might necessitate a graph database.
Database Partitioning and High-Volume Online Ticketing Systems
High-volume online ticketing systems, like those used for concerts or sporting events, often face massive concurrent access and data retrieval demands. Database partitioning, or sharding, addresses this by horizontally dividing the database into smaller, more manageable pieces. Each partition can reside on a separate server, distributing the workload and improving performance. For instance, a ticketing system might partition its database by event, with each event’s data stored on a separate partition. This means that queries for tickets to a specific event only need to access the relevant partition, reducing the load on the entire database. This strategy ensures faster response times and higher throughput, even during peak demand periods, effectively improving the user experience and preventing system overload.
Database Replication Strategies for High Availability and Fault Tolerance
Ensuring high availability and fault tolerance is critical for business-critical applications. Database replication creates copies of the database on multiple servers. If one server fails, another server can take over seamlessly, minimizing downtime. Several replication strategies exist: synchronous replication ensures data consistency across all replicas, but can reduce performance; asynchronous replication prioritizes performance, accepting a slight lag in data consistency. Master-slave replication designates one server as the primary (master) and others as secondary (slaves), which receive updates from the master. More sophisticated techniques, such as multi-master replication, allow updates on multiple servers, improving write performance. For a critical business application like an online banking system, a robust replication strategy, possibly employing synchronous replication and failover mechanisms, is essential to maintain continuous service and prevent data loss. A real-world example is seen in many large e-commerce sites that employ geographically distributed databases with replication to ensure low latency and high availability for users worldwide.
Data Migration and Business Transformation
Data migration, the process of moving data from one system to another, is a critical component of any business transformation initiative involving database systems. Successful migration requires meticulous planning, execution, and validation to ensure data integrity and minimal disruption to ongoing operations. The complexity increases significantly when dealing with legacy systems and large volumes of transactional data. This section details key considerations for a smooth and effective data migration process.
Data migration from a legacy system to a new database system involves several key steps. Proper planning and execution are crucial for minimizing disruption and ensuring data integrity.
Key Steps in Data Migration
A phased approach is generally recommended, starting with a thorough assessment of the legacy system and its data. This includes identifying data sources, data quality issues, and dependencies. Subsequently, a target database schema is designed, taking into account the requirements of the new system. Data cleansing and transformation are performed to ensure consistency and accuracy. Testing and validation are critical to identify and correct any errors before the final cutover. Finally, post-migration monitoring is essential to ensure the new system operates as expected. Each phase involves specific tasks and considerations that must be addressed to ensure a successful migration.
Challenges of Aligning Database Schema with Evolving Business Processes
Maintaining alignment between a database schema and an organization’s evolving business processes presents ongoing challenges. Business processes are dynamic, often requiring modifications to the database structure to accommodate new features, functionalities, or regulatory changes. These changes can introduce inconsistencies if not carefully managed. For instance, adding a new customer attribute or changing the way orders are processed necessitates corresponding schema modifications. Failure to address these changes appropriately can lead to data integrity issues, inaccurate reporting, and system instability. Therefore, a robust change management process is essential.
Documenting the Impact of Database Changes
Effective communication and documentation are vital to manage the impact of database changes on various business units and stakeholders. A well-defined process for documenting these impacts ensures transparency and minimizes disruptions. This involves identifying affected stakeholders, assessing the potential impact of changes on their operations, and communicating the changes in a clear and timely manner. A comprehensive impact assessment should be conducted prior to implementing any database modifications.
| Business Unit | Affected Process | Impact of Change | Mitigation Strategy |
|---|---|---|---|
| Sales | Order Processing | Potential delays in order fulfillment due to new validation rules. | Provide training to sales staff on new processes; implement a phased rollout. |
| Marketing | Customer Segmentation | Changes to customer data fields may require adjustments to reporting dashboards. | Update reporting dashboards to reflect the new data structure; provide training to marketing analysts. |
| Finance | Financial Reporting | New data fields may require adjustments to financial reporting systems. | Integrate the new data fields into existing financial reporting systems; conduct thorough testing. |
| Customer Service | Customer Inquiry Handling | Changes to data access may impact the ability to quickly retrieve customer information. | Update customer service tools to reflect the new data structure; provide training to customer service representatives. |
Minimizing Data Loss During Large-Scale Data Migration
Minimizing data loss during a large-scale data migration, particularly one involving a high volume of transactional data, demands a robust strategy. This includes employing techniques such as data replication, checksum verification, and transaction logging. Data replication creates multiple copies of the data, reducing the risk of data loss due to hardware failure or other unforeseen events. Checksum verification ensures data integrity by comparing checksums before and after migration. Transaction logging provides a detailed record of all database transactions, allowing for rollback in case of errors. Regular backups throughout the migration process are also crucial. Furthermore, a thorough testing phase is essential to identify and resolve any potential data loss issues before the final cutover.
Data Security and Business Compliance: A Database Must Reflect The Business Processes Of An Organization.

Protecting sensitive customer data in a CRM database is paramount, demanding a robust security framework aligned with industry regulations like GDPR, CCPA, and HIPAA, depending on the geographic location and the nature of the data. Failure to implement adequate security measures can lead to significant financial losses, reputational damage, and legal repercussions. This section details essential security measures for a CRM database, focusing on access control, encryption, and data masking techniques.
Data security in a CRM system necessitates a multi-layered approach, encompassing both technical and procedural safeguards. A well-defined security strategy minimizes vulnerabilities and ensures compliance with relevant regulations, protecting the organization and its customers. The following sections detail specific techniques for implementing these safeguards.
Access Control Mechanisms
Access control mechanisms are fundamental to data security. They define who can access specific data and what actions they are permitted to perform. Implementing a role-based access control (RBAC) system is highly recommended. This system assigns users to specific roles (e.g., Sales Representative, Marketing Manager, Administrator) each with predefined permissions. For instance, a Sales Representative might have read and write access to customer contact information but not to financial data, while an Administrator would have comprehensive access. This granular control prevents unauthorized access and ensures that only authorized personnel can perform specific actions, aligning with the principle of least privilege. Regular audits of user roles and permissions are essential to maintain security and identify potential vulnerabilities. The implementation should also include robust password policies and multi-factor authentication to further strengthen security.
Data Encryption Techniques
Data encryption is a crucial technique for protecting sensitive information both at rest and in transit. Encryption transforms readable data (plaintext) into an unreadable format (ciphertext) using a cryptographic key. For data at rest, encryption should be applied to the entire database or specific sensitive fields like credit card numbers or social security numbers. Common encryption algorithms include AES (Advanced Encryption Standard) and RSA (Rivest-Shamir-Adleman). For data in transit, HTTPS (Hypertext Transfer Protocol Secure) should be used to encrypt communication between the CRM system and its users. Regular key management and rotation are crucial to maintaining the effectiveness of encryption. Key management practices should adhere to best practices to prevent unauthorized access or compromise. The encryption algorithm chosen should be robust and up-to-date, resistant to known attacks.
Data Masking Techniques, A database must reflect the business processes of an organization.
Data masking is a technique used to protect sensitive data while still allowing access for testing, development, and other non-production purposes. It involves replacing sensitive data with non-sensitive substitutes that maintain the data structure and format but hide the actual values. For example, a credit card number might be masked by replacing all digits except the last four with Xs (e.g., XXXX-XXXX-XXXX-1234). This allows developers to test applications without compromising real customer data. Different masking techniques exist, including character substitution, data shuffling, and data generation. The choice of technique depends on the specific sensitivity of the data and the purpose of the masked data. A well-defined data masking strategy ensures that sensitive data remains protected throughout the software development lifecycle. For instance, a development environment could utilize fully masked data, while a testing environment might use partially masked data to simulate real-world scenarios. This approach provides a balance between data security and the needs of development and testing teams.





